Data QA: Why You Need It & How to Do It
By Mia Dor and Ido Zehori
“Gaining deep familiarity with a dataset starts with the understanding that, before reaching them, the dataset already underwent an elaborate journey. Thus, before data professionals begin their research, they must understand every aspect of that journey.”
Data QA: Why You Need It & How to Do It

By Mia Dor and Ido Zehori
Experienced data professionals (data scientists, data analysts, data engineers, etc.) will be familiar with the saying “garbage in, garbage out.” Put simply, basing research on bad data will result in bad conclusions. To avoid this, it’s crucial that, before doing anything else, data scientists first get to know the data they’re looking at.
Gaining deep familiarity with a dataset starts with the understanding that, before reaching them, the dataset already underwent an elaborate journey. Thus, before data professionals begin their research, they must understand every aspect of that journey.
The first step of Data QA is understanding the data gathering process. To this end, some of the questions data scientists will need to ask first include:
How was this data gathered or created?
Was it created by a system that logs data or a survey? Was it composed by a specific device? If so, does the device run automatically or manually? Were any bugs or other issues, such as a system timeout, encountered during the data collection period?
Who handled the data up to this point?
Did the people managing the data until now apply any filters to it? Did they introduce any biases by only collecting data from a portion of relevant available sources or by eliminating data that might have been relevant? Is there any data I’m not seeing?
Does the data contain any filters?
The data collection process may have unintentionally implemented some filters if, for example, not all of the data collection methods or devices were employed equivalently.
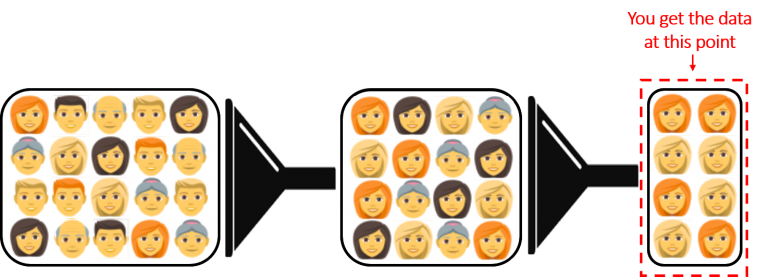
The data you received may have been filtered at an earlier stage of collection.
Before they begin their research, data scientists must be certain about two things: whether there is any data they are missing and whether the data they are inspecting has undergone any changes.
Once they’re clear about the journey a dataset has taken and any filters or biases have been uncovered, data professionals can begin performing Data QA. This article offers general guidelines for performing the two stages of Data QA: Apriori Data Validation and Statistical Data Validation. Performing these Data QA steps is critical before beginning research. Through a solid Data QA process, data scientists can ensure that the information they base their research on is sound.
Apriori Data Validation
Apriori Data Validation describes the process of reviewing all of the fields in the data and formulating the rules and conditions that cannot exist in a dataset you can trust.
Take, for example, a dataset indicating conversions from an ad, where a click is necessary for a conversion to have occurred. This condition defines the relationship between the conversion column and the click column. Since a conversion cannot exist without a click, the value TRUE for a conversion cannot appear alongside a FALSE value for a click in the same row.
Data professionals must examine a dataset and describe the relationships between the various columns and rows in a very detailed way. They must identify the strict rules these relationships must follow for the data to be deemed trustworthy.
As another example, consider a dataset with a field for cities and a field for states. If the dataset has LA and NY paired, this doesn’t make sense. The state field must contain a state, and the city indicated within the associated city field must exist within that state. A rule must therefore be defined accordingly.
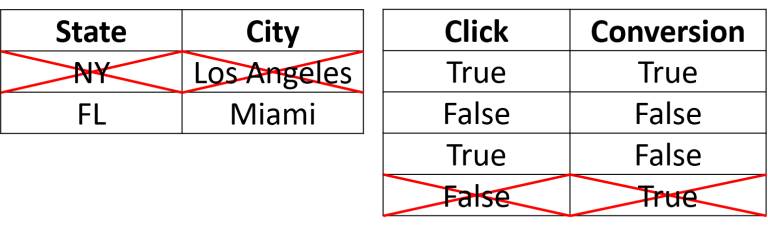
Examples of Illogical Data
Through careful examination of the information set before them, data professionals must formulate the questions and answers needed to validate that the data they’re looking at can be relied upon for research. But how will a data scientist know which questions to ask? The answer is simple: do their homework!
An excellent place to start is by looking at the data column by column and contemplating on the relationships at play between each of them. Data scientists should consider that a column can be viewed as an entity—a piece of data that resides in a community of fellow columns. A row, as an entity, is the sum of the information of its columns and is also the relationship between them. Data professionals need to make sure they start with the smallest component within these communities, the single value, and gradually zoom out and map its relationship to the other “atoms”—the values in the other columns that, all together, form a “molecule” that is the row itself.
Here are some rules to consider when performing Apriori Data Validation:
Questions that should also be asked during Apriori Data Validation include:
If possible, data professionals should also compare the data they have with ground truth—information provided by direct observation. For example, suppose a company has direct access to the GPS of a user’s device. In that case, the company should verify whether that user has visited a certain location as indicated within the dataset.
If, during Apriori Data Validation, the data fails any test, the data professional should notify the data owner and resolve the issue before relying on this data for their research. While this circumstance is both good news and bad news (the data can’t be trusted, but a bug has been discovered), understanding why the data has failed the test will help solve further problems down the line that might not have otherwise been detected.
Statistical Data Validation
In the second stage of Data QA, Statistical Data Validation, data professionals must verify whether the data they see matches what they’d expect to see. This subtle process involves questioning everything. Data scientists should take nothing as it is—they should consider, for example, whether the data they’re looking at goes in line with their intuition, expertise, and whether it makes sense alongside other datasets they have in hand.
In Statistical Data Validation, data scientists use their domain knowledge and knowledge of the system to truly pick apart the data and understand the “why” behind it. We recommend starting by writing down the conditions they would expect to find. For example, if your system serves one million users daily, you would expect the daily count reflected in the data to be in the neighborhood of that amount. If the data indicated only 100,000 users in a given month, this would indicate an issue that would be uncovered during Statistical Data Validation but not during Apriori Data Validation.
Additional examples of conditions to be explored during Statistical Data Validation include:
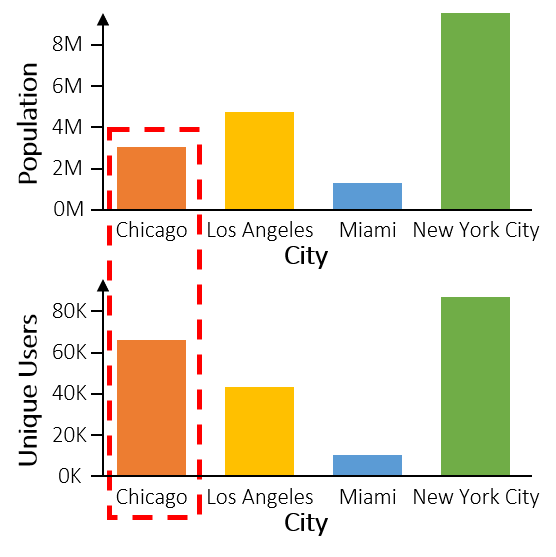
The number of users in Chicago is much larger than in other cities, relative to their size.
As mentioned, Statistical Data Validation requires domain knowledge as well as knowledge of the system. Domain knowledge can reveal, for example, whether the amount of user churn for a specific timeframe being indicated in the dataset is actually within the usual or expected range. As another example, if you are an ad company, you should know the ballpark figure for how many ads you’ve served. If you only see data from a thousand different publishers, but you know you should see data from hundreds of millions, there is something wrong with the data.
How should you treat the results of the validation test?
An understanding of what’s expected is critical for Statistical Data Validation. Calculating the descriptive statistics of a column without first having some intuition on what you’d expect to find might lead you to the known bias of justifying whatever you will find. This is not the correct approach. Ideally, the data professional will have an idea of what they expect to see, and the dataset should align with that expectation. If it doesn’t, you should be curious about the contrast; does it exist because your expectations were off, or have you uncovered something faulty in the data?
It is also important to understand how many of the rows contain problematic data. If there are only a few such rows, it may not be worth considering these errors and correcting them since this is a relatively small amount of data. It’s common to find problems with data; not finding any is nearly impossible.
Specifically, if the data does look perfect, it would be wise to suspect some sort of issue. If there are no data outliers or nulls, you should check whether the data has been cleaned up at an earlier stage. Such a cleaning process may have added noise and unwanted biases to the data.
Conclusion
When you implement the Data QA process we’ve outlined here, you’ll be amazed by the number of bugs that exist in the data writing process that you’ve never even noticed. These bugs are why many people fail to deliver results; it’s not because of bad model selection or bad feature engineering. It’s because the critical process of QAing the data was overlooked.
But the fact of the matter is, while Data QA is essential, it’s also tedious, time-consuming, and error-prone. It’s easy to forget to ask relevant questions and therefore miss relevant details.
Even when you find that your data is biased and contains errors, this doesn’t mean it can’t be used. It means the data professional must be aware of the biases and errors and understand that the research results are relevant only to the context in which the research was done. For example, if an early filter is performed and the data remaining is from a particular country, then the study results would be relevant only to that country, and deducing what is true in other countries it is not necessarily possible with the given dataset.
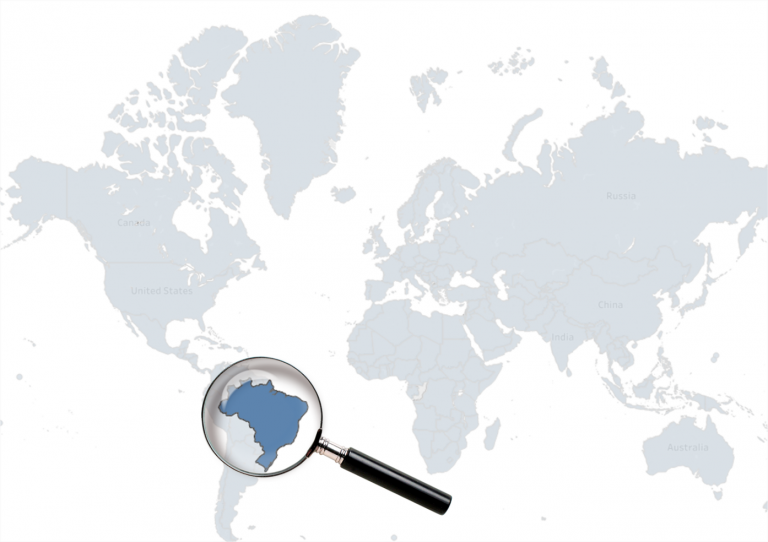
The conclusions of a study based on data from a single country will be relevant only to that country.
In light of all of the work and unknowns involved in Data QAing, we’ve developed a tool that automates much of the work for you. We take data very seriously, and our tool eliminates the possibility that any research will be based on bad data. Our Data QA tool scans every dataset and reports all of the errors it uncovers. With this, we’re able to ensure that we avoid “garbage in, garbage out” with research and conclusions based on solid, trustworthy data. To help answer any questions or start integrating our innovative tools please click the “Contact Us’ button below.